Series vs Dataframe
 |
 |
Dropping
| Series | Dataframe |
| s.drop(['a', 'c']) | df.drop('Contury', axis=1) |
Sorting (Dataframe)
| df.sort_values(by='Country') # Column 이름으로 정렬 |
I/O
| Read & Write to CSV | df = pd.read_csv( 'file.csv', header=None, nrows=5) df.to_csv('myDataFrame.csv') |
| Read & Write to Excel | df = pd.read_excel('file.xlsx') df.to_excel('myDataFrame.xlsx' , sheet_name='Sheet1') |
| ※ 복수 시트중 특정 시트만 선택 xlsx = pd.ExcelFile('file.xlsx') df = pd.read_excel(xlsx, 'Sheet1') |
|
| Read & Write to SQL Query or DB | from sqlalchemy import create_engine engine = create_engine('sqlite://:memory: ') df = pd.read_sql('SELECT * FROM my_table;' , engine) df = pd.read_sql_table('my_table' , engine) df = pd.read_sql_query('SELECT * FROM my_table;' , engine) ※ df 를 myDf 테이블로 DB에 등록 df.to_sql('myDf', engine) |
Selection
| import pandas as pd values= [ ['Rohan',455], ['Elvish',250], ['Deepak',495], ['Soni',400], ['Radhika',350], ['Vansh',450] ] df = pd.DataFrame(values, columns=['Name', 'Total_Marks'])  |
| df.iloc | 칼럼지정은 인덱스만 사용 ※ 범위는 마지막 인덱스는 제외 |
df.iloc[1:3] # [처음row인덱스 : 마지막제외row인덱스] = df.iloc[1:3, : ] # 전체칼럼은 생략하거나 : 를 사용 = df.iloc[[1,2]] # [ , , ] 를 사용해 특정 row 번호를 지정  df.iloc[ : , [0, 1]] # 특정 row, column 을 지정할 시엔 [ , , ] 를 사용 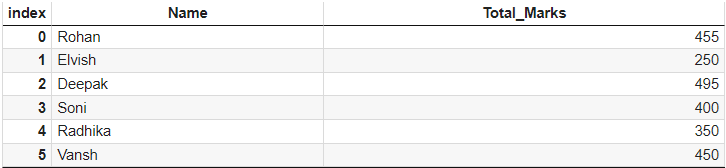 |
| df.loc | 칼럼 지정은 칼럼명만 사용 ※ 범위는 제외없이 모두 포함 |
df.loc[1: 3, ['Name', 'Total_Marks] # 칼럼명 지정 = df.loc[1:3,'Name' :'Total_Marks'] # 칼럼범위 지정  # 로의 필터df.loc[df['Total_Marks'] > 400, ['Name', 'Total_Marks'] ]  |
| df.iat | 칼럼 지정은 인덱스만 사용하여 한개만 추출 | df.iat[2, 1] |
| df.at | 칼럼 지정은 칼럼명만 사용하여 한개만 추출 | df.at[2, 'Total_Marks'] |
Apply Functions
| 1. 특정 칼럼의 값을 조작하여 새로운 칼럼을 생성 (Dataframe.assign()) | ||
| import pandas as pd values= [ ['Rohan',455], ['Elvish',250], ['Deepak',495], ['Soni',400], ['Radhika',350], ['Vansh',450] ] df = pd.DataFrame(values, columns=['Name', 'Total_Marks'])  # lambda 함수정의 : Total_Marks 칼럼값을 1/5 f = lambda row : (row[ 'Total_Marks' ] /500 * 100) # assing 으로 lambda 함수를 적용하고 결과로 Percentage 칼럼을 생성 df = df.assign(Percentage = f) # 혹은, apply() 를 이용 f = lambda row: (row[ 'Total_Marks'] / 500 * 100) df[ 'Percentage' ] = df.apply(f, axis=1) # 혹은, 특정칼럼만 선택해서 apply() 를 적용 df[ 'Percentage' ] = df[ 'Total_Marks' ].apply(lambda col: col / 500 * 100)  |
||
| 2. 특정 조건에 맞는 값만 변경 | ||
| values_list = [[15, 2.5, 100], [20, 4.5, 50], [25, 5.2, 80], [45, 5.8, 48], [40, 6.3, 70], [41, 6.4, 90], [51, 2.3, 111]] df = pd.DataFrame(values_list, columns=['Field_1', 'Field_2', 'Field_3'], index=['a', 'b', 'c', 'd', 'e', 'f', 'g'])  |
||
| 단수 칼럼만 변경 # lambda 함수정의 : 인덱스(x.name)가 'd' 만 2승 f = lambda row: np.square(row) if row.name == 'd' else row # 칼럼(axis=1) 방향 적용 df = df.apply(f, axis=1) 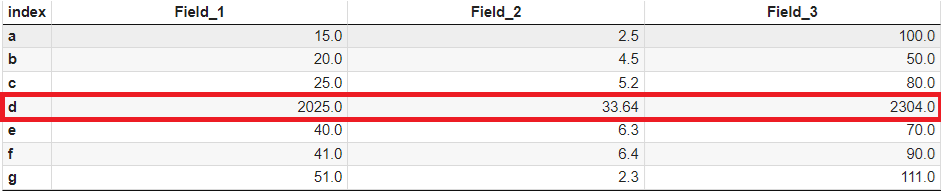 |
||
| 복수 칼럼 변경 f = lambda row: np.square(row) if row.name in ['a', 'e', 'g'] else row df = df.apply(f, axis=1)  |
||
'data science > pandas' 카테고리의 다른 글
| Sales data 분석 (0) | 2025.03.12 |
|---|---|
| 복수의 DataFrame들을 수직방향으로 통합하기 (0) | 2025.03.12 |
| 두개의 Series를 하나의 DataFrame으로 통합 (0) | 2025.03.12 |
| (pandas) Youtube 노빠꾸탁재훈 채널 분석 (0) | 2023.11.18 |
| (pandas) 분석용 youtube 채널 데이터(DataFrame) 만들기 (1) | 2023.11.18 |