아래는 https://jalammar.github.io/illustrated-word2vec/ 사이트를 내 나름대로 간단히 설명한 것이다.
Language Modeling
스마트폰에서 문장을 입력할때 다음 단어를 예측하는 것도 자연언어처리를 이용하는 것이다.
 |
 |
||
간단하게 모델을 표현하면 아래와 같다.

실질적으로 모델은 하나의 출력이 아니라 모든 단어의 가능성의 스코어를 출력하고 키보드 어플리케이션은 가장 스코어가 높은 순서로 표시를 하게 된다.

이제 학습된 모델 내부를 들여다 보면, 1) 각 단어의 Embedding을 참조하고 2) 이를 예측의 계산에 사용한다.
 |
 |
Language Model Training
window slide
예제 문장 : “Thou shalt not make a machine in the likeness of a human mind”
윈도우 사이즈=3 일 경우에 아래와 같이 3 단어씩 슬라이딩 하면서 오른쪽으로 이동하며 이때 처음 두 단어가 input 이고 마지막 한 단어가 output 으로 Dataset 을 구성.



Look both ways

위에서 본것 처럼 마지막 단어를 예측하는 방식이라 하면 블랭크에 들어가는 단어는 bus 일 가능성이 크다고 예측할 수 있다. 하지만 아래와 같이 bus 가 블랭크 다음에 위치한다면 red 가 가장 적합하다고 할 수 있다.

한쪽방향보다는 양쪽방향을 참조하느게 보다 정확한 결과를 얻을 수 있음을 알 수 있다.
Continuous Bag of Words (CBOW)
주위의 단어들(window)를 입력으로하여 블랭크 단어를 예측하는 아키텍쳐를 Continuous Bag of Words 라고 한다.
 |
 |
Skipgram
CBOW 와 반대로 현재 단어(window의 중심)로 주위의 단어를 예측하는 아키텍쳐를 Skip-gram 이라 한다.



(데이터세트를 만든 다음) training process
첫번째 단어 "not" 을 입력으로 하여 주위의 단어를 예측해 보자.

맨 처음에는 모델이 학습되지 않은 상태(Untrained Model)에서 예측을 하게 된다. 당연히 정확하지 않은 결과를 얻게 된다.
 thou 보다 taco 가 스코어가 높게 나왔다. |
 Actual Target 은 thou 가 가장 높은 스코어 |
|
차기 학습에서는 에러(Actual Target - Model Prediction)를 모델 파라미터에 업데이트를 하게 된다.

이를 모든 데이터세트 단어에 대해 적용하게 되고 이를 학습의 한 사이클인 1 epoch 라고 칭하게 된다. 수회 epoch 의 학습을 통해 파라미터들이 갱신 됨으로서 정확한 결과를 얻게 된다.
Negative Sampling
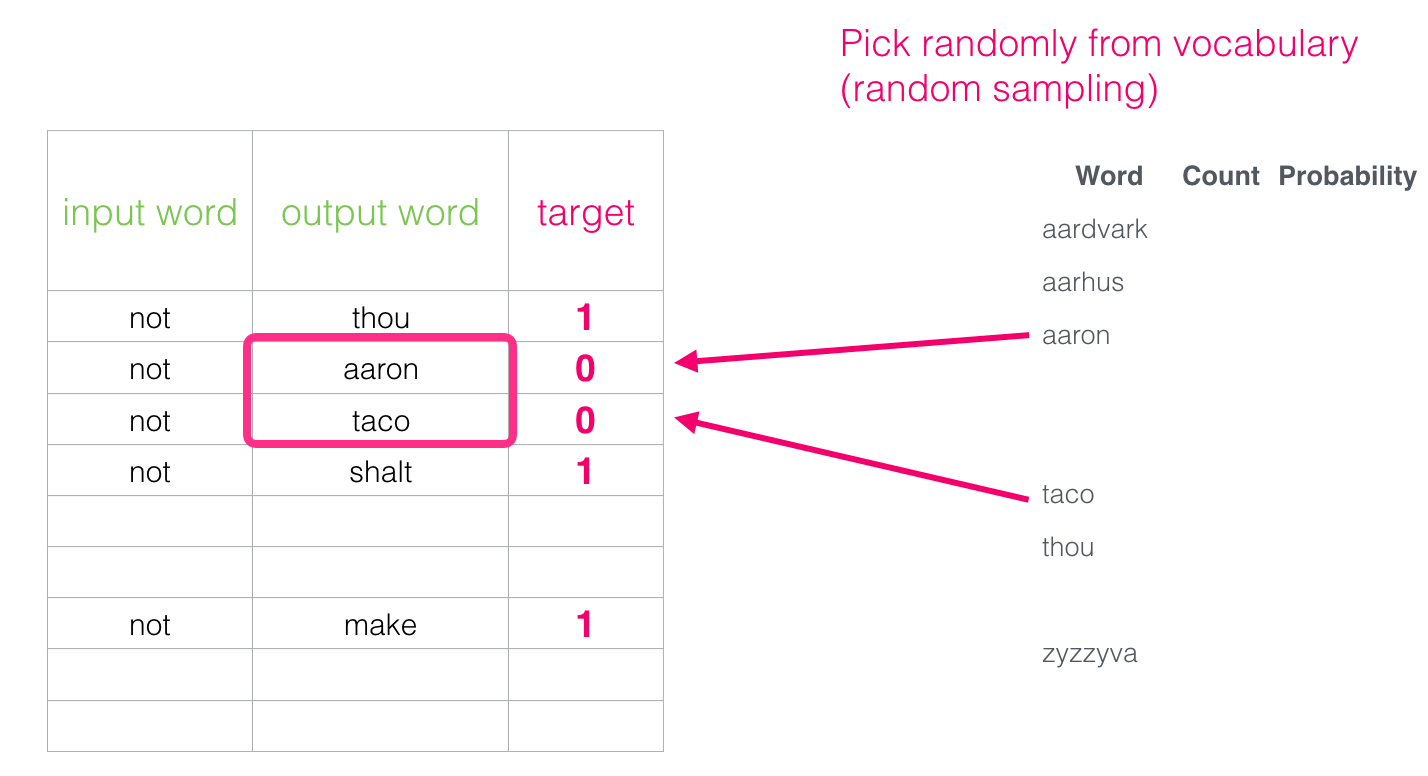
입력을 바로 타겟으로 출력하는 것은 계산적으로 힘든 작업이기 때문에 아래와 같이 입력단어의 주위 단어를 1로 표현하는 데이터세트로 변경하자.

하지만 오직 주위 단어들만 데이터세트로 만들면 모델은 결국 모두 1을 출력하는 결과를 얻게 될 것이다. 이를 방지하기 위해서 False 데이터(=Negative examples)를 삽입할 필요가 있다.
Negative examples 의 출력단어(output word)는 랜덤 샘플로 채우도록 한다.
'자연언어처리 (NLP)' 카테고리의 다른 글
| stopwords (0) | 2024.03.13 |
|---|---|
| 워드 토큰화 (0) | 2024.03.13 |
| (Word2Vec) model training (1) | 2023.12.21 |
| (Word2Vec) training (1) | 2023.12.17 |
| (Word2Vec) 1. 개념 (1) | 2023.12.17 |



